
Clickstream Data Feed
21 May 2017 » Analytics Tips
One trend that I have seen in the last few years is the interest of my customers in getting the raw data out of the Adobe Marketing Cloud. More and more corporations are hiring data analysts and these people want all the data they can get. Using various tools (R, Hadoop, Data Workbench…), it is possible to dig deeper into the data to uncover hidden gems or create more sophisticated reports. Today I will explain the raw data from Adobe Analytics, the clickstream data feed.
Setting up the clickstream data feed
Until not that long ago, setting the data feed required a consultant or client care. Now, any Analytics administrator can create them. Just go to “Admin” > “Data Feeds”. Click then on the “+ Add” button. You will get to the configuration page (click for full size screenshot):
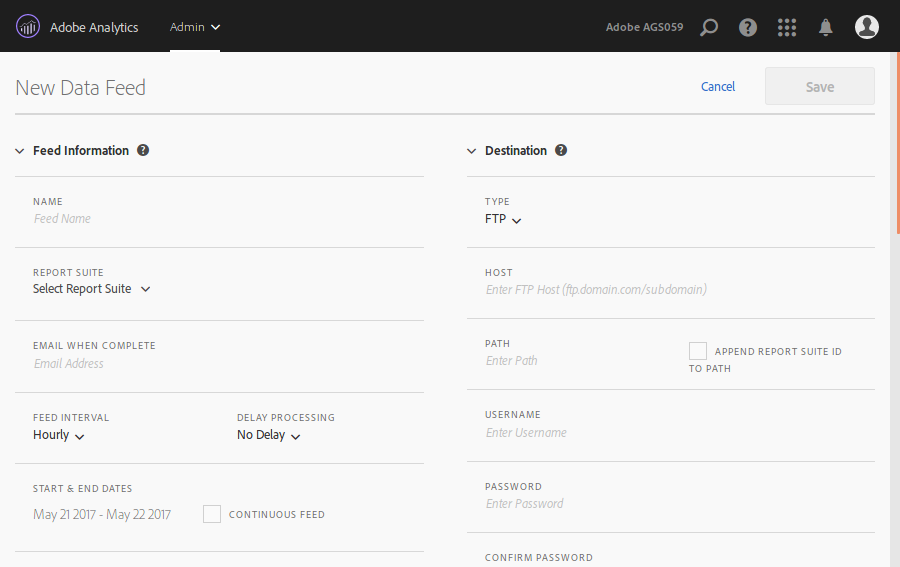
There are a lot of parameters, most of them are self explanatory. I will just mention those that need a bit of further explanation:
- Feed interval. Set it to either daily or hourly. In either case, you should be aware that the feed is not sent immediately, but there is a delay which can be of a few hours.
- Delay processing. I do not see a reason for any value other than “No Delay”.
- Compression format. I am a Linux fan, but even in this case, I recommend Zip format.
- Packaging type. I always recommend “Single File”, to get a single ZIP archive with all the files you need in it.
- Manifest. I guess some people find it useful, but not me, so I never include it.
Finally, you need to select the columns. There is a great temptation to select all columns, but I strongly recommend against it. Selecting all columns can end up creating data swamps, with information you are never going to use. Instead, my recommendation is to select the latest recommended non-premium template.
Once you have created the data feed, make sure it is in active mode. If not, activate it manually.
Pre and post variables
Before I continue, I need to explain the difference between pre and post variables. In fact, when we talk about “pre” variables, we mean mean variables with a “pre_” prefix or without any prefix at all.
- Variables with “pre_” prefix. These are variables usually populated by Adobe. I have yet to come across a use of these and they are not available in the Analytics interface. However, you can request them via client care. In general, you can safely ignore them.
- Variables without prefix. These variables are, either the values that come directly from the hit, or values inferred from others in the hit. In other words, if you were using an HTTP sniffer, these are the values you would have seen in the Analytics calls.
-
Variables with a “post_” prefix. These are values generated in the early stages of the data processing and are the values that will show up in the reports. One would expect to see a copy of the value form the hit in the post column, but there are various reasons why this might not be the case:
-
The virtual cookie. As you know, eVars have a persistence, so you do not need to set them on every call. Adobe’s servers keep track of the current stored value, the expiration and whether they are first touch or last touch. There are two cases when the pre and post eVar values will be different:
- If the eVar is set to last touch and the hit does not contain any value for that eVar, the post_evar column will contain the current stored value of the eVar.
- If the eVar is set to first touch and the virtual cookie already has a a value for that eVar, the post_evar column will contain the current stored value, irrespective of the value coming from the hit.
- Server-side processing. Both VISTA rules and processing rules can modify the value of most Analytics variables. The new values will only be reflected in the post column.
-
The virtual cookie. As you know, eVars have a persistence, so you do not need to set them on every call. Adobe’s servers keep track of the current stored value, the expiration and whether they are first touch or last touch. There are two cases when the pre and post eVar values will be different:
Contents of the data feed
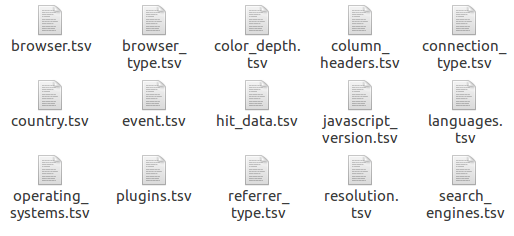 Once you unzip a clickstream data feed archive, you will see several files. The first thing to notice is the extension: TSV. This means that the contents of all files are separated by tabs, not commas. The main file is the hit_data.tsv and it is usually the largest file. This file contains one row per hit and, as I have just mentioned, the fields are tab-separated. You will need to process this file in conjunction with the column_header.tsv, which identifies the columns of the hit_data.tsv.
Once you unzip a clickstream data feed archive, you will see several files. The first thing to notice is the extension: TSV. This means that the contents of all files are separated by tabs, not commas. The main file is the hit_data.tsv and it is usually the largest file. This file contains one row per hit and, as I have just mentioned, the fields are tab-separated. You will need to process this file in conjunction with the column_header.tsv, which identifies the columns of the hit_data.tsv.
All other files contain lookup tables. Columns like browser, country or event will show numbers or comma-separated list of numbers. In order to decode this numbers, you will need these auxiliary files.
Visitor Identification
Identifying the different visitors tends to be quite tricky. Follow these steps to get that identification right:
- Exclude all rows in hit_data.tsv with
exclude_hit > 0. - Exclude all rows with
hit_source = 5,7,8,9. - Combine
post_visid_highandpost_visid_low.
With these two columns combined, you now have a unique ID that identified a visitor across multiple visits. For example, counting the total number of unique values will give you the unique visitor count.
What next?
Well, this is up to your imagination. A clickstream data feed can be used for many different things. What you now have is the same raw data Adobe Analytics uses to create the reports, so the possibilities are endless. Some capabilities you can built from this data, not available in Analytics:
- Attribution modelling. In Analytics Standard you only get first and last touch attribution models. If you want more sophisticated models, you can build them using the raw data.
- Cross device identification. If you are capturing a CRM ID of some sort, you can detect how a user moves from one device to another. This can be combined with the previous use case for cross visit & cross device modelling.
- Custom reports. Although Adobe Analytics offers great flexibility to create reports, you might need a particular combination of data or calculated metric not available in the UI.
While you are analysing your data, it is a good idea to compare your numbers with those appearing in the UI, when Adobe Analytics offers them. This will help you validate your calculations.
Finally, just a word of caution. Do not try to dive directly into the data immediately. First, you will need to familiarise yourself with the data format, especially in cases like events and products.
Link to official Adobe documentation: https://marketing.adobe.com/resources/help/en_US/reference/analytics-data-feed.html.