
The Data Lake
21 May 2023 » Platform
Any system that stores a decent amount of data ends up needing a data lake. The Adobe Experience Platform (AEP) is no exception and there is surely one, which will be today’s topic. I want to particularly focus on the misconceptions, with the hope that you understand this building block and know how to use it.
Definition
According to Wikipedia, a data lake is:
[…] a system or repository of data stored in its natural/raw format, usually object blobs or files.
Apparently, it was first coined in 2011. That date seems about right, as, until then, the more common term that was used was data mart.
While this is a generic definition, in the case of AEP, a more apt definition of the Data Lake would be:
Storage of data for analytical workloads.
This definition is in clear contrast with the definition I gave for the Real-Time Customer Profile (RTCP) in my previous post, which is the central location of the engagement workloads. The Data Lake is at the heart of the analysis and insights world within AEP.
Data Structure
As with everything in AEP, all data in the Data Lake must be structured following an XDM schema and stored in a dataset. There is also a data catalog, which I am not going to explain.
Looking at the previous paragraph and excluding the data catalog, one may think that RTCP and Data Lake are almost identical. So, if this is not the case, where are the differences? I would highlight the following:
| RTCP | Data Lake |
|---|---|
| Only datasets enabled for profile | All datasets |
| Only stores the last value received for a profile attribute | All historical values are available |
| Experience Events expire with TTL | All Experience Events |
| Real-time | Batch |
I assume that now the difference is clear: RTCP has only a small subset of the available data, whereas the Data Lake stores all the data.
Before I continue, I want to express a word of caution based on what I have just said. Some Adobe customers, upon understanding how the Data Lake works, will want to dump all their data in the Data Lake. I am sure that you know where I am going to:
- The Data Lake is only meant to store data for your data analysis and insights. Therefore, only load the data you need for your reporting and analysis.
- The Data Lake was not designed to be your system of record; is a tool for digital marketing.
- Check your contract, as it should include the maximum Data Lake size you are entitled to.
Access
Everything I have explained so far is useless if you cannot access the data. This is where things get interesting for the Data Lake, as there are many options to access or use its data. Let me remind you again that the main purpose of this building block is analysis and insights, which are shown in the access methods documented below.
For reference, I am including again the architecture diagram I am basing this series of posts on, as it will facilitate the understanding.

Customer Journey Analytics
Adobe has created its own tool to show and analyze the data: Customer Journey Analytics (CJA). If you are familiar with Adobe Analytics, you will see that CJA has a similar look and feel. However, there is an important difference between the two:
- Adobe Analytics was originally designed to analyze web behavioral data. Since app behavioral data is similar in general, it can also be used for it. However, any other type of data is difficult to load and work with.
- Customer Journey Analytics can work on any timestamped data; more specifically, on datasets with Experience Events. These events can be of multiple types: web clickstream, purchases (both online and offline), calls to a call center, email interactions (sends, opens, clicks…), etc. This is what the name of this application wants to reflect: you can analyze all touchpoints of a customer with your company.
I will not try to even introduce CJA; it would require its own series of posts. Maybe for another day. For now, I can refer you to the Customer Journey Analytics overview in the Experience League.
Data Access API
It is also possible to extract the datasets in the Data Lake in file format. To do that, you will need to use the Data Access API. This API allows you to download the files and work with them in your own data lake.
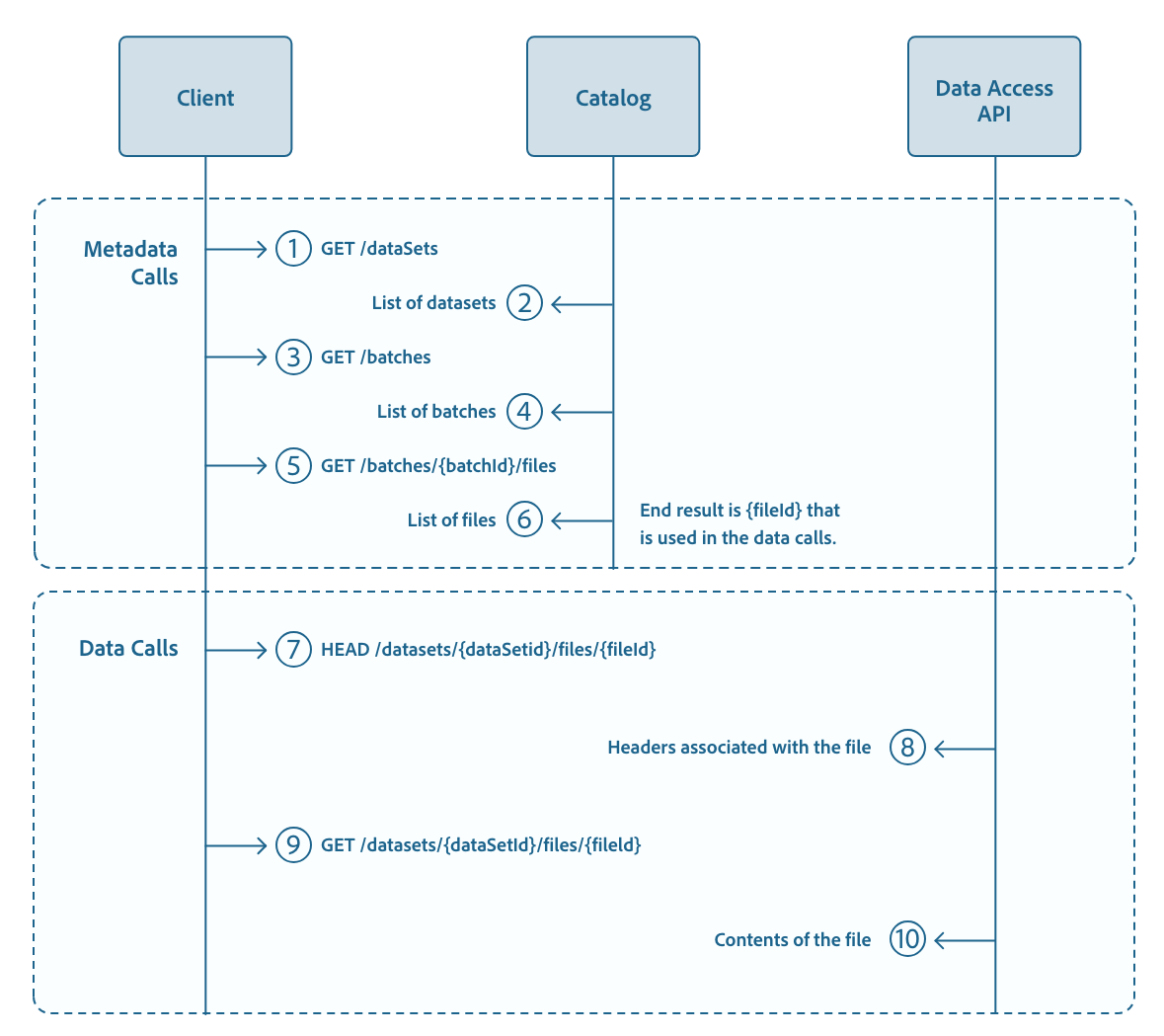
The process to download the files requires a few steps. Initially, it may seem too complex, but you will immediately understand that it is necessary.
- Get the list of datasets from the Catalog API.
- Find the dataset you are interested in. You may be able to skip these 2 steps if you already have that information.
- Get the list of batches for a particular dataset from the Catalog API.
- Iterate through all batches or select the batch that you want to download.
- Get the list of files for the current batch from the Catalog API.
- Get the metadata of the file from the Data Access API.
- Download the file through the Data Access API.
The following sequence diagram from the Experience League shows it graphically:
PostgreSQL Interface
You can also connect your BI tool of choice to the Data Lake. AEP offers a PostgreSQL-compatible interface. It is important to highlight the word “compatible”: the Data Lake does not use PostgreSQL nor any other RDBMS engine. This interface is just a convenient way of accessing the data. You can think of the XDM schema as the column names and each entry in the dataset as a row. With this, you can issue SELECT statements to get the data that you want.
If you have the PostgreSQL command line application (psql) installed, you can play with it by copying and pasting the PSQL command that you get from the AEP interface:
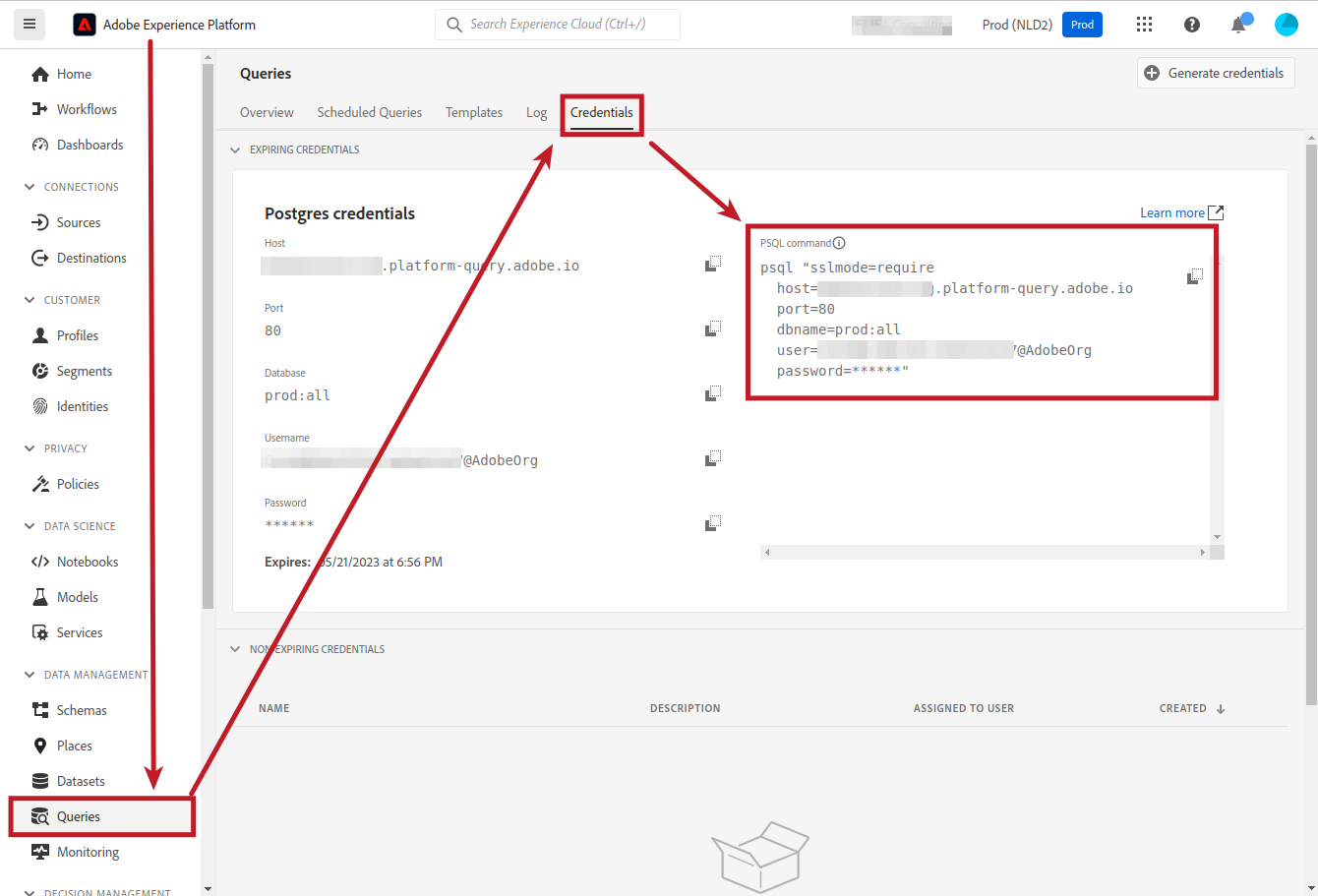
Check with your Adobe representative to confirm that your license allows you to access the PostgreSQL interface and the limits that you have.
Discovery & Insights
Last, but not least, we have the “Discovery & Insights” building block, just below the Data Lake in the architecture diagram. I will explain it in more detail in a future blog post. To summarize, it offers two main capabilities:
- Query Services, which is an interface to issue SQL commands. Think of it as the PostgreSQL interface I have just mentioned, but embedded in the AEP UI.
- Intelligence & AI, which offers some ML & AI capabilities.