
Enable for Profile
11 Sep 2022 » Platform
I have mentioned a few times the expression enable for profile, without explaining what it really meant and how to play with it. I wanted to document it a few months ago when I started writing more about the Adobe Experience Platform (AEP). However, as usual, I realised that I had to first explain some background before addressing this concept. This is what I have done in the past few posts, but now you should have all you need to understand it.
What is it?
If you are familiar with AEP’s UI, both schema and dataset attributes have a toggle with the label “Profile”:
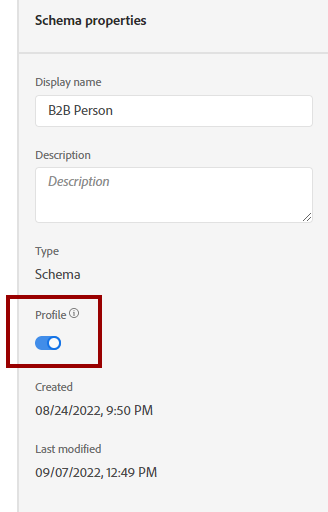
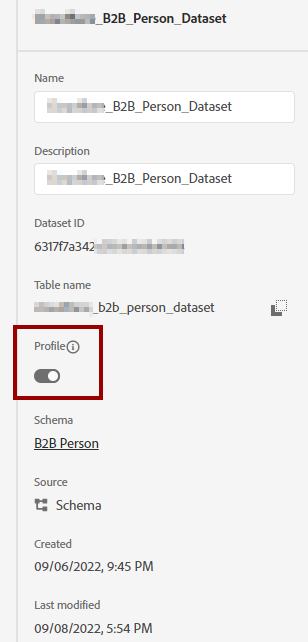
I am sure many of you will be asking now: “What is this toggle for?” While I am not the engineer who designed it, I can provide an initial description. Again, I will use the following architecture diagram:

When you create a new schema or a new dataset, nothing happens in the Real-Time Customer Profile functionality. Any data sent to the dataset will go only to the Data Lake. In some cases, this may be enough, for example, if you plan to use the data only in Query Services or Customer Journey Analytics.
In the most common scenario, though, you will want the data to be part of the unified profile. This only happens when you enable the schema and the dataset for profile. It may sound like a stupid design decision: “Why do I need to take an extra step when I always want my data in the profile?”
One-way road
The answer to the previous question is that, once you switch the “Profile” toggle on of a schema and its corresponding dataset, there is no going back. The following happens after enabling this feature:
- The schema is permanently added to the unified schema
- Schema fields cannot be moved, deleted or changed
- Identity namespaces are permanently added to the identity service
- Identities received from ingested data will permanently populate the identity graph
As you can see, if you make a mistake, you will probably not be able to fix it. If you forgot to include a field in the schema, you are in luck, as you can still add it. However, for any other change in the schema, your only option is to reset the whole sandbox and start again from scratch. This means deleting and creating again schemas, datasets, data sources, destinations… In the particular case of identity namespaces, they cannot be deleted.
I hope that, by now, you have already realised how key this feature is and how delicate it also is. If you enable it too early, bad things will happen.
Process
I do not want to scare you, just to warn you. You have to be very methodic and understand everything you do. I suggest the following procedure, which you should tweak for your particular case.
As with any development, you should start in a development sandbox. Remember that these sandboxes can only ingest a maximum of 10% of the total number of profiles in your contract.
- Create the schemas; do not enable for profile
- Create the datasets; do not enable for profile
- Manually ingest sample data and validate the schema against it
- Configure the data sources
- Ingest more sample data (up to 10% of your entitlement) through the data sources
- Validate the data using Query Services (SQL)
This is an iterative process. Any time you realise that you need to do some changes to the schema, you need to go back to step 3 and continue. Once you are sure the schema will not require any major changes, you should proceed to the next steps, still in development.
- Delete all batches from the datasets
- Enable schemas and datasets for profile
- Ingest again data from the data sources (up to 10% of entitlement)
- Validate the data again using Query Services (SQL)
- If all validations have passed, you can now continue with the implementation of the services: RTCDP, AJO and CJA
This last step is just a placeholder. Depending on your license and requirement, it will require more or less work. Expect at least one month of work there. If, after enabling for profile, you find that you need to modify the schema, you will have to reset the development sandbox. This situation is more common than what you would expect and there can be many reasons for it:
- The AEP services have found that important data is missing
- There was an error in the schema which went unnoticed
- The requirements have changed
It is therefore recommended that you have a set of scripts or use Postman, to be able to easily recreate all schemas and datasets through AEP’s API. Remember that the only exception is if you just need to add new fields, which you can do at any time.
Once you have validated everything in development and everything is working as expected, you can move to production. There, you should apply the same process above.
Photo by Adrienn