
Datasets
28 Aug 2022 » Platform
Creating an XMD schema does not also create storage for this schema. A schema is just a data model, not the data itself. To get the data in Adobe Experience Platform, you need to create datasets, which conform to schemas. In other words, the datasets are the storage where the ingested data is stored.
I always repeat that AEP is not a SQL database, but it is inevitable to sometimes compare both, as SQL databases are more familiar. If it helps you understand the difference between a dataset and an XDM schema, I would say that the XDM schema is like a CREATE TABLE script, where you define the table. Once you execute this script in an RDBMS, the engine reserves some storage for the table, where data can be inserted. This is the equivalent of the dataset.
Data Lake
Datasets live in the data lake. This applies to both streaming and batch ingestion. Although it may be too obvious for some, I have to explain it as this statement has consequences that you will learn as you deepen your AEP knowledge. Here you have some examples:
- You only get data in the Unified Profile if the dataset and the schema are both enabled for profile. Unless you know exactly what you are doing, do not enable your dataset for profile just yet. I will write about it next time.
- Once this configuration parameter has been enabled, the contents of the Unified Profile are only a subset of the data in the data lake.
- Customer Journey Analytics (CJA) only uses the data lake.
- The Data Access API only allows you to access data in the data lake.
For reference, you may want to review this diagram:

Create
You can create as many datasets as you want, although it is generally recommended to create one dataset per schema.
To create a dataset, you should first go to the Datasets menu entry on the left and click on “+ Create dataset”
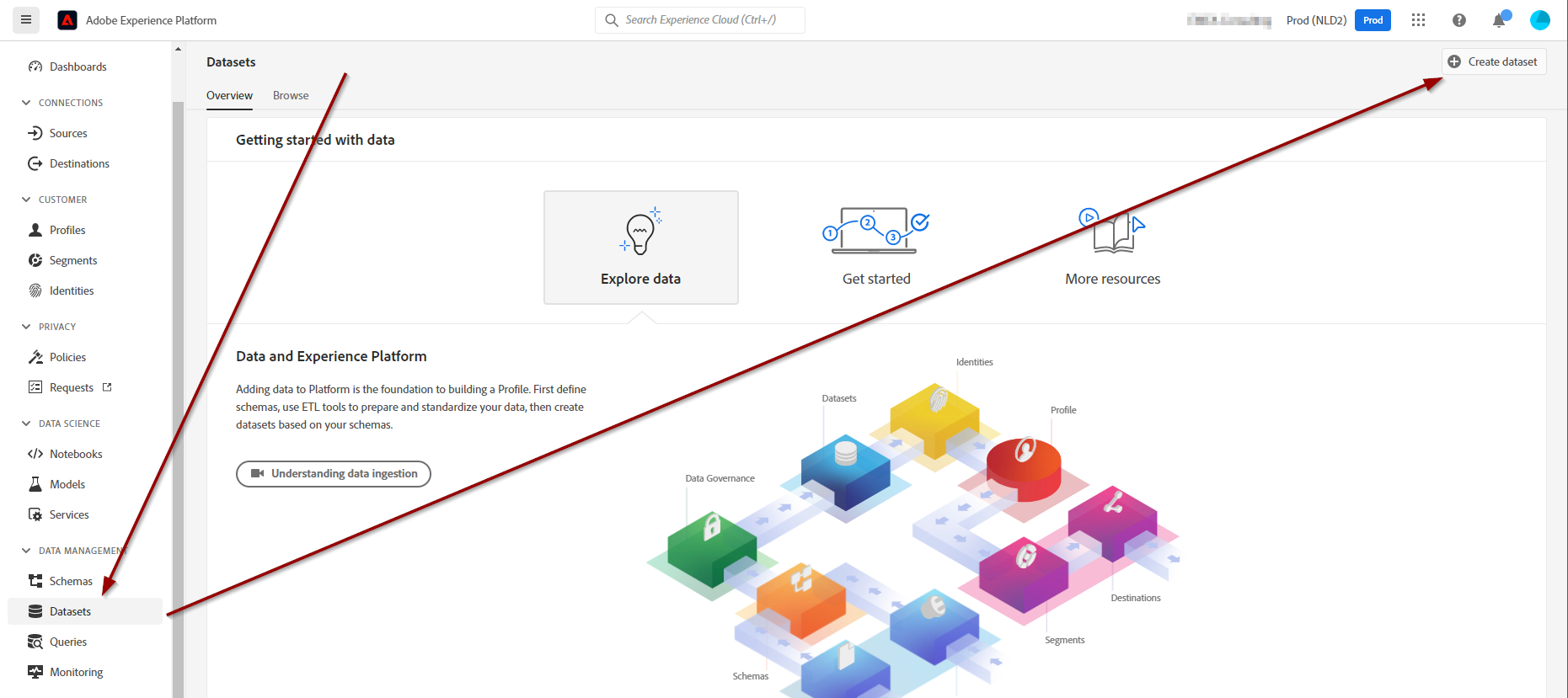
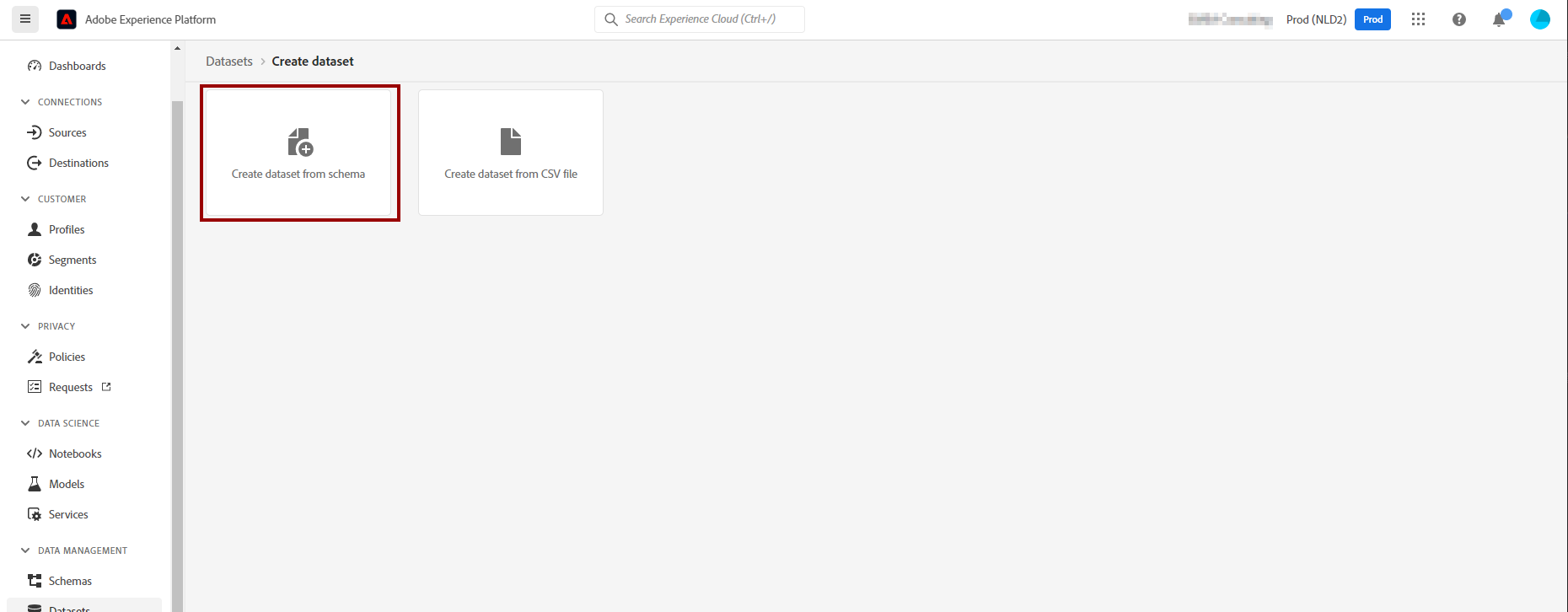
On the next screen, select “Create dataset from schema”. The option to create a dataset from CSV is just for testing purposes.
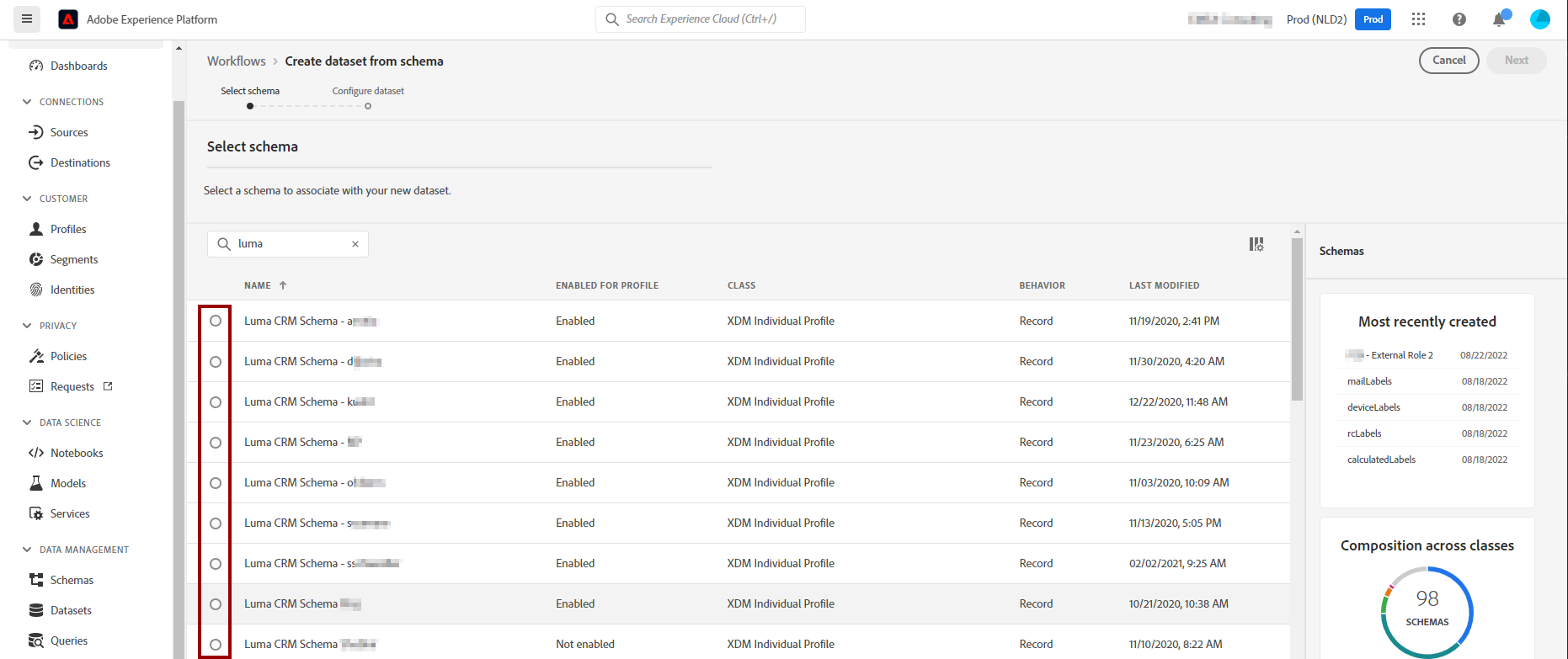
Now you can select the XDM schema that you want to use for this dataset and click “Next”.
You finalize by giving it a name and a description. You should follow a naming convention and put enough information in the description so that you remember in 6 months what this dataset is for. Click “Finish”.
Populate
I will not explain in this post how to insert data. This part will require its own blog post and, even if I write about it, it would be limited. In summary, you need to connect a data source with a dataset through a workflow. There are dozens of source connectors available in AEP, with more being developed.
For now, what is important to know is that there are two broad types of data sources:
- Streaming. This is for data that is ingested in real-time and you also want the profile to be updated in real-time.
- Batch. Well, I do not think I need to explain this one: data is loaded in batches, usually from files or external systems like databases.
However, all data ingested through any source connector is sent to the data lake in batches. Yes, even streaming data is stored in a temporary location and grouped into micro-batches. Remember that data lakes and real-time do not mix well, at least for now.
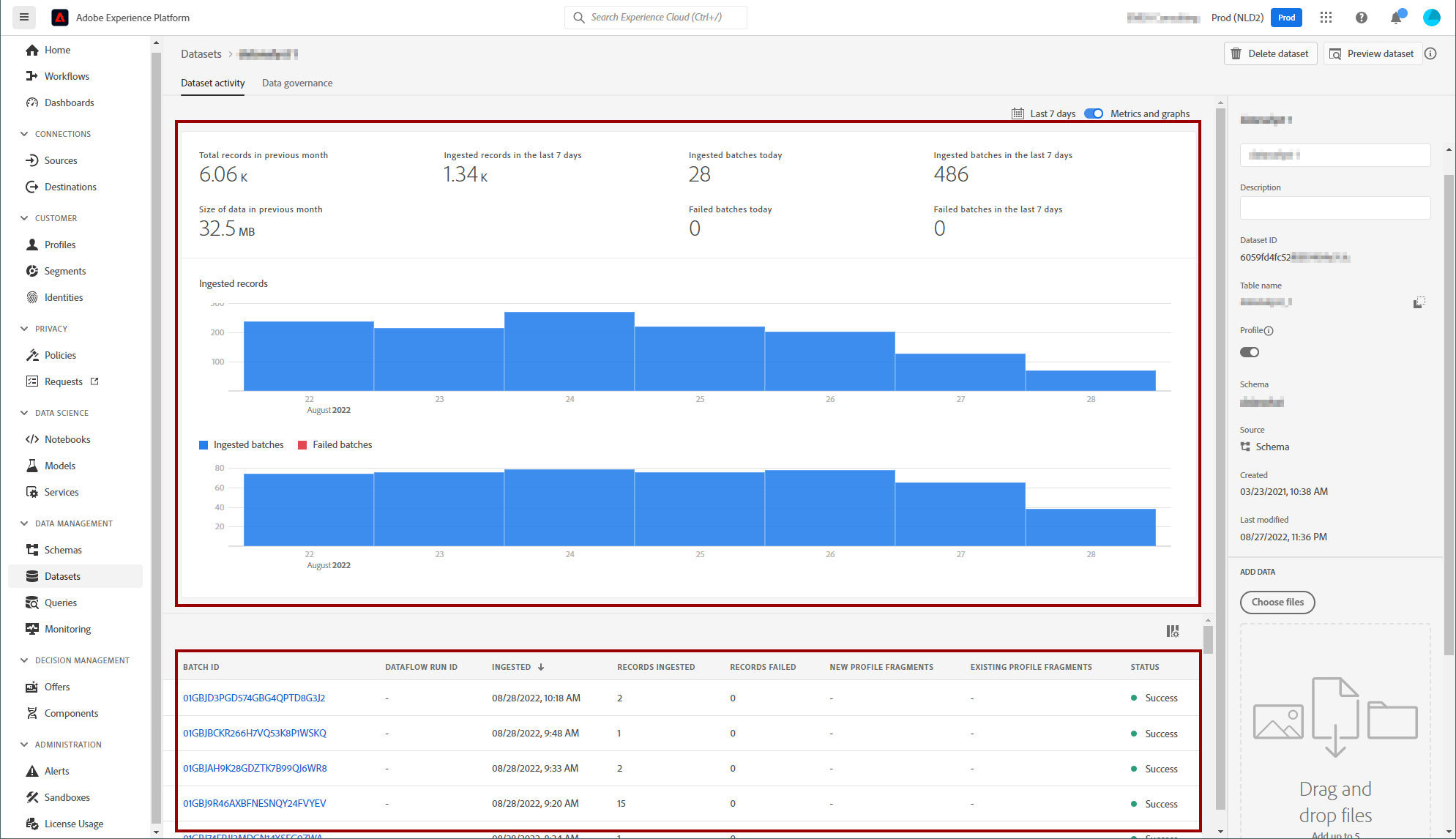
You can review how the dataset is performing by clicking on a dataset. You will see at the top a report of successful and failed batches and a list of batches at the bottom of the screen.
Preview
There is no way to see the full contents of a dataset through the UI. It does not make any sense anyway. If you have 5 million profiles, you are never going to review all of them manually. What you can do is preview the contents:
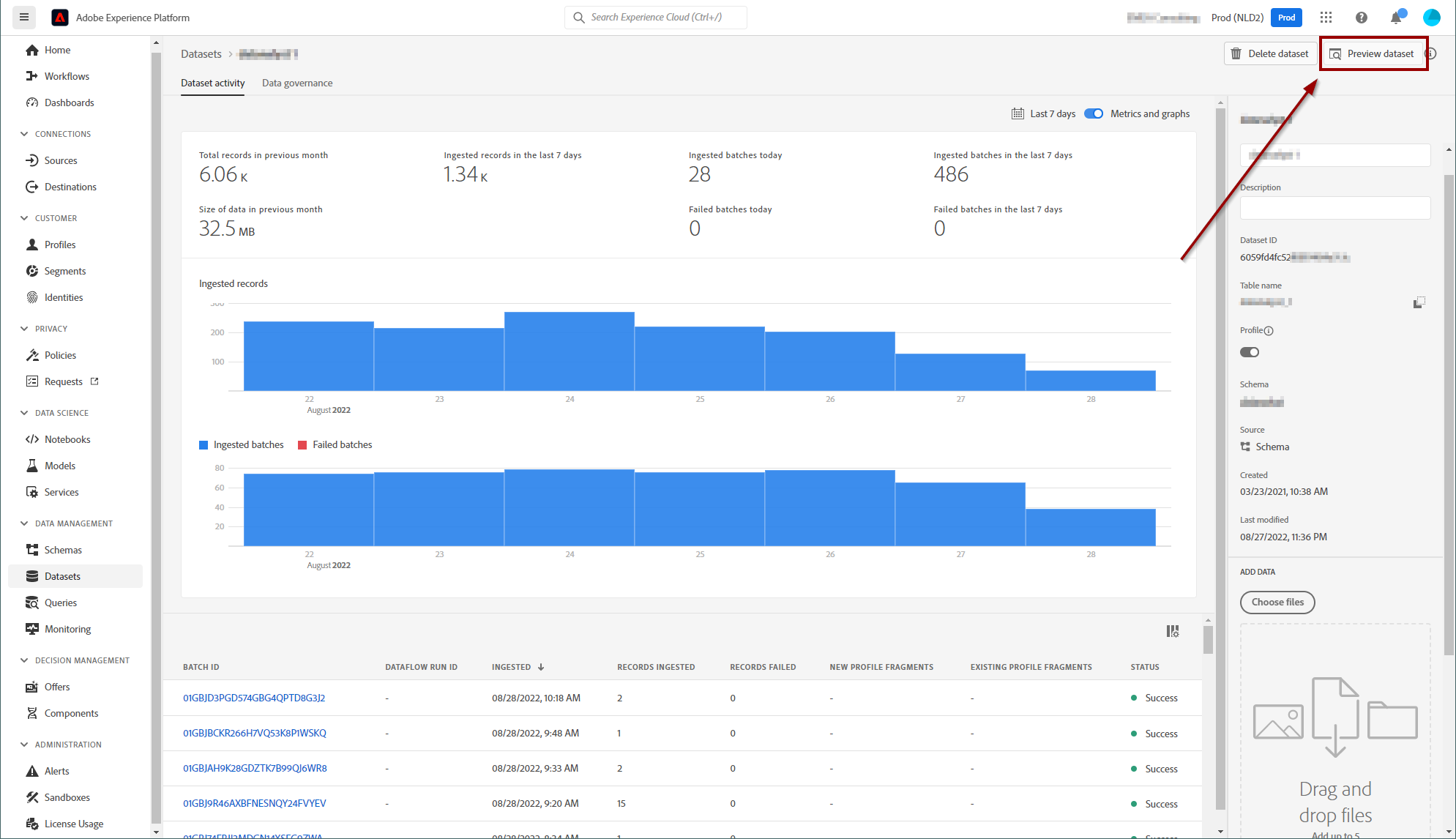
Clicking on that button will show a sample of the records in the dataset. Unfortunately, you have no control over this sample.
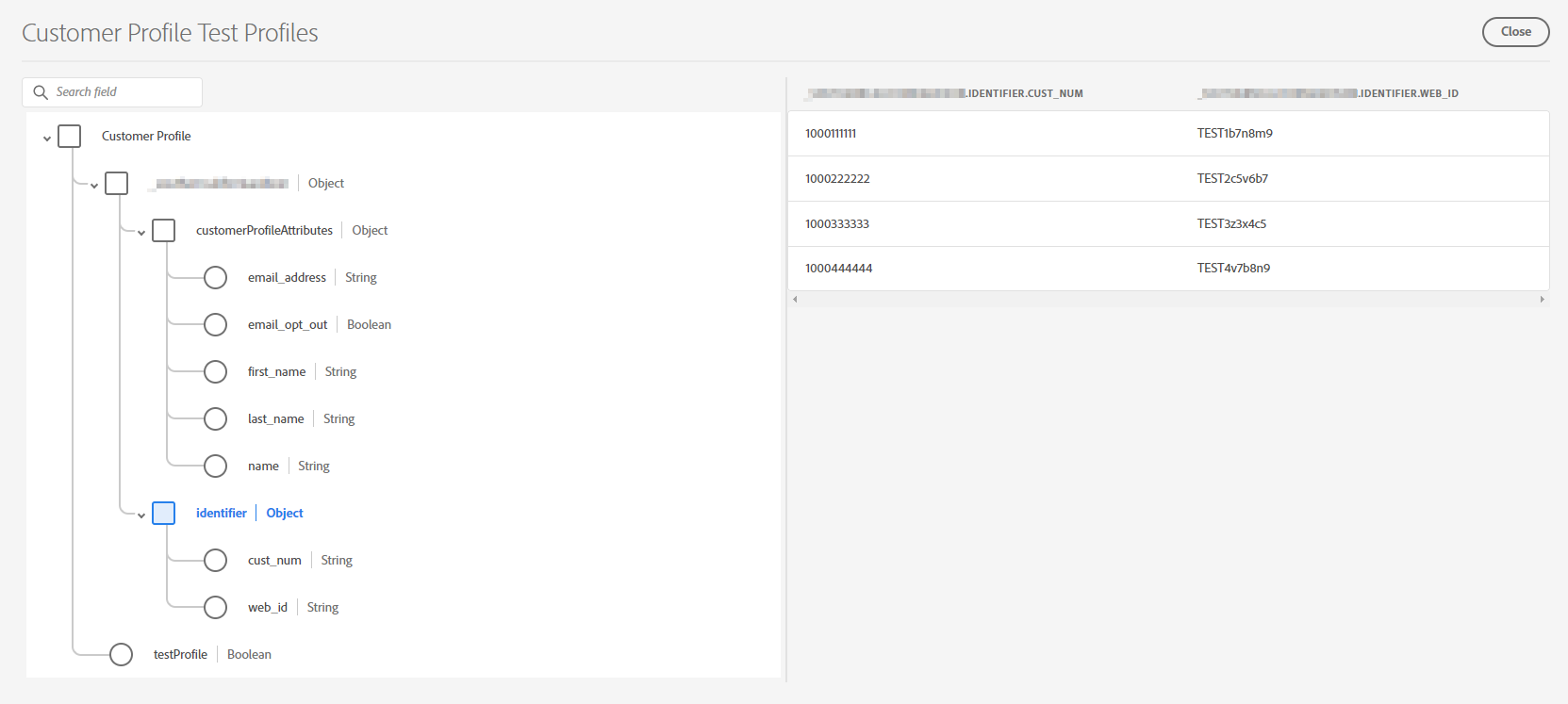
You can use the schema on the left to filter what you see on the right, by clicking on the data fields or objects. This feature is very useful at the beginning of the implementation, to check if the data you are ingesting looks good.
Delete
The final operation with a dataset is to delete it. You probably have already seen the button on the top right of the dataset overview. As expected, this will delete both the data in the dataset and the dataset itself. However, you may want to only delete the data, partially or totally. For this, you can click on a batch and, on the following screen, delete it.
Inserts or updates
Yes, I know, in the previous section I said “final operation”. Datasets do not support other operations like inserting in a specific location or updating existing data. All you can do is append additional data to the dataset and, through merge policies, make sure that the last batch replaces previous data in the unified profile.
Photo by Joshua Sortino on Unsplash