
Look-alike modelling
27 Sep 2020 » AAM
In one of my first blog posts I mentioned look-alike modelling in AAM. However, I did not explain this concept in detail back then and I think it is high time I amend this omission. I will also show how to configure it and use its output.
What is look-alike modelling anyway?
Let’s start with the basic: a definition. You can find many with a quick Internet search, but if you want my definition, here you have my attempt:
Finding audiences within the unknown visitors to a website, who look and act like a known audience.
Since I do not have a masters degree in English to craft a better definition, I will complement it with an example.
Consider a website with 1,000,000 visitors per day. Every day, 5,000 convert, which means that 995,000 visitors just browsed the website. There may be multiple reasons why they did not convert: not what they were looking for, too expensive, could not find what they wanted, not ready to buy… It is clear that those who think it is too expensive are very unlikely to buy in the future, so we can ignore them. On the other hand, those who are not ready to buy yet are our perfect target. The question is: how do we know who, from those 995,000 visitors, are likely to buy in the future? One possible answer is: those who are very similar to the 5,000 who converted. And this is what look-alike modelling is about: identify anonymous visitors who are similar to those we already know we are interested in.
Since AAM works with traits, the concept of “similar” means “with many traits in common”. This is the trait-weight algorithm:
- Take a known audience (e.g. visitors who convert).
- Create a prioritised list of traits that the visitors within this audience have in common.
- Take the rest of the population outside this audience and look for visitors who have many of these traits.
Obviously, the algorithm is much more complex, but you get the idea.
Creating the model
Let’s now jump to AAM and see how you would do it. You start by creating what is called “the model”. In the top menu, go to Audience Data > Models. There you have both predictive audiences and look-alike models. We will ignore the former for now. Click on “Add new”:
Give it a name and a description. Expand the Configuration section, which is where the fun starts!
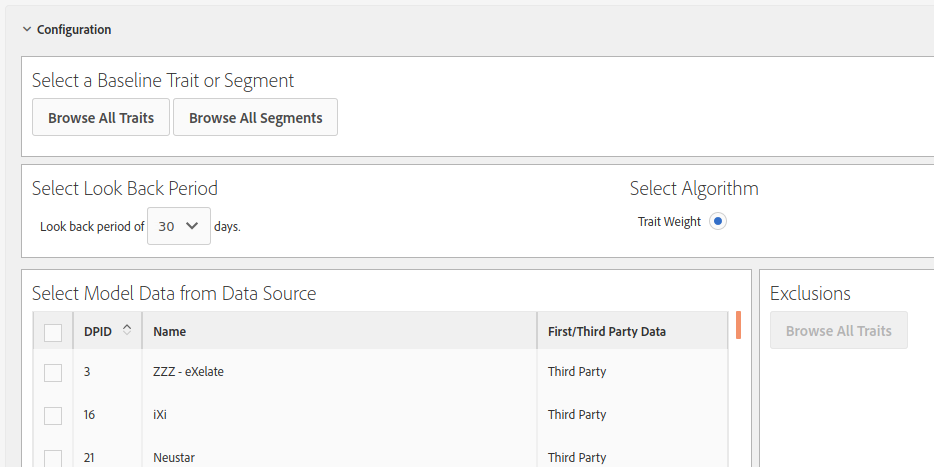
- Select a Baseline Trait or Segment. This is your known audience, those visitors who exhibit a behaviour that we are interested in. In my example above, this would a trait or segment identifying visitors who convert (5,000 daily).
- Select Look Back Period. Visitors qualify and disqualify for traits continuously. This is the period in which you want to check for trait qualification.
- Select Algorithm. Currently AAM only supports one algorithm, so nothing for you to do here.
- Select Model Data from Data Source. Select the data sources with the traits that should be used by the algorithm.
- Exclusions. Traits from the previous data sources to exclude from the algorithm.
Click on “Save”.
Traits and data sources
You may be scratching your head about the last two points of the previous section. Data sources? Exclusion? That deserves some explanation.
For the trait-weight algorithm, all traits are created equal, but we know that that there some traits more interesting than others. A trait of “visited the home page” has very little meaning when comparing audiences: most of the visitors will exhibit this trait and the fact that to visitors visited the home page does not make them any similar. On the other hand, a trait of “living in London” may be more interesting, if it turns out that your conversions happen mainly in this city.
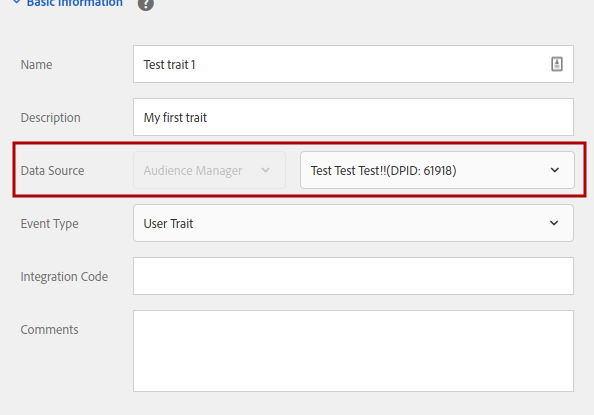 So, you need to tell the algorithm which traits you think will be better for your purposes. And you do that by selecting the data source of the trait:
So, you need to tell the algorithm which traits you think will be better for your purposes. And you do that by selecting the data source of the trait:
- Rule-based traits. When creating this type of trait, you are free to choose any data source. It is just a classification of traits, with no other influence in the processing of the data. You may need to create new data sources to classify your rule-based traits to fit your needs.
- Onboarded traits. In both 1st and 3rd party data, the data source is closely related to the origin of the data.
In most of the cases, your 1st party traits will not be enough to run a model. Generally, look-alike modelling works best with 3rd party data. Think about it for a minute. Knowing that a visitor has abandoned the basked is good, it shows interest in the products or services, but you do not need an ML algorithm for it. However, knowing that your purchasers are female, between 30 and 45, living in the suburbs and with a disposable income of $500/month, is gold; it is just that you would not be able to find this by yourself. You will likely need to buy this information from a 3rd party and use an algorithm to find the correlations.
Running the model
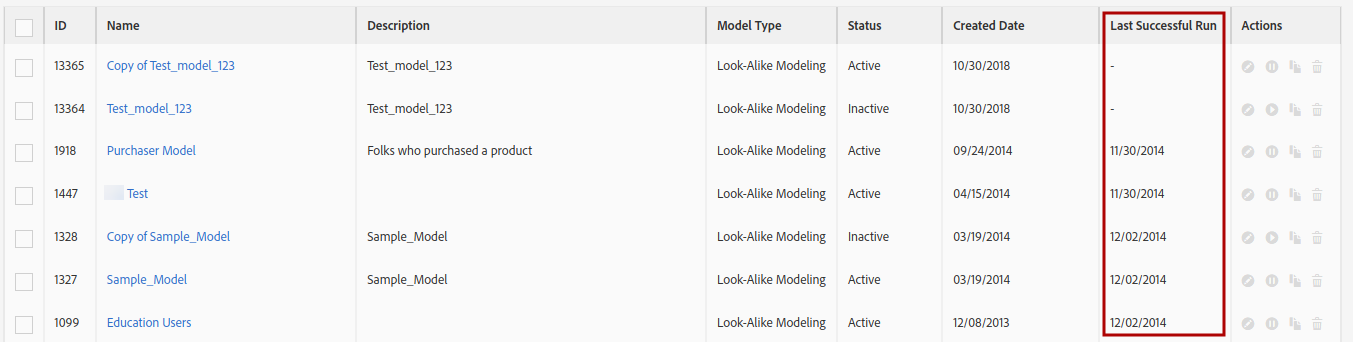
After you have set it up, you need to let it “bake”. This algorithm is not real-time and is only executed once every 7 days. For the impatient, this is more than enough, people do not change drastically every week. You can check when a model was last executed in the “Last Successful Run” column:
Once it has run once, you should check the results. Ideally, the graph in the “Model Reach & Accuracy” should look something like:
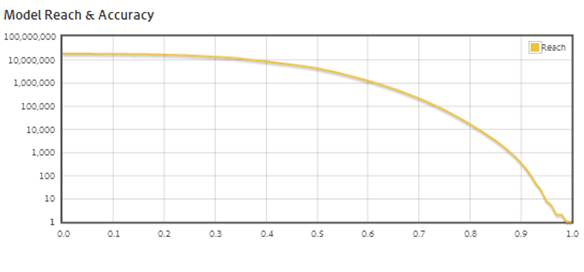
What is is basically saying is that, for an accuracy of 1 (right-most), you get the baseline. As you move to the left, your audience increases, but you are including visitor whose traits are more and more different to the baseline (lower accuracy).
The more your shape departs from the ideal, the worse the output is. If you did not get it right, you will need to fiddle with the traits:
- Excluding more traits, especially if they show under “Influential traits” and you feel like they do not make sense.
- Adding more traits from other data sources.
I am afraid that there is little science here: you will need to play by the ear until you get a shape that makes sense.
Creating an algorithmic trait
Once you have a model that is finally working, it is time to use it. Since we are in Audience Manager, the way to feed the output of the algorithm back into the system is through a trait. In case you were wondering what was an algorithmic model, now you finally know:
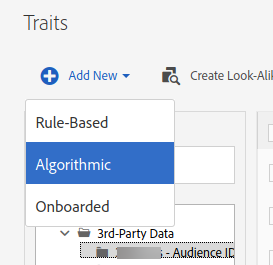
As usual, you start by choosing a name, a description, a data source for classification purposes and a folder.
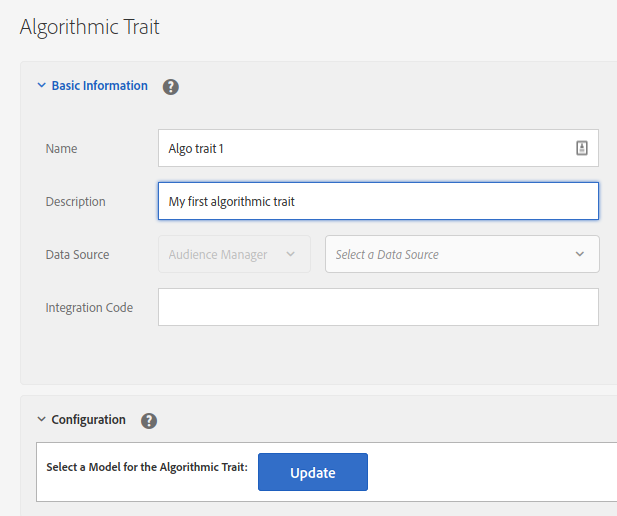
Then, moving on to the Configuration section, you need to choose two main things:
-
The model. You may have multiple models running in parallel, so you start by choosing which one, after clicking on “Update”.
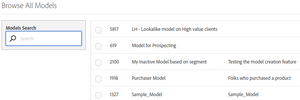
- The accuracy. You need to decide whether you want a small audience, but very accurate or a bigger audience with lower accuracy. My recommendation is to choose, at least, 80% accuracy, or more.

Remember to click on “Save”.
What this will do is:
- Run the algorithm every ~7 days.
- Assign the trait to those visitors who qualify for the accuracy.
You can then use the trait in any of your segments. Typically, you will want bid more to advertise your products/services to the visitors who qualify for the trait. You know that they are fairly similar to other visitors who have converted in the past and you hope that they are more likely to convert.