
Data Sources in AAM
30 Sep 2018 » AAM
When you are new to AAM and you hear the words “data sources”, you immediately think you understand the concept. However, as you progress in your knowledge of the tool, you start to realise that you actually do not know what data sources are in AAM and need to rethink all you have learned. At least, this is what happened to me. Over time, I have finally understood this concept and today I wanted to share it with you in this post.
Onboarded traits
The actual etymological meaning still stands in one case: onboarded traits. AAM separates input files by data source. In other words, when you create an onboarded trait, you must select the correct data source from the drop-down:
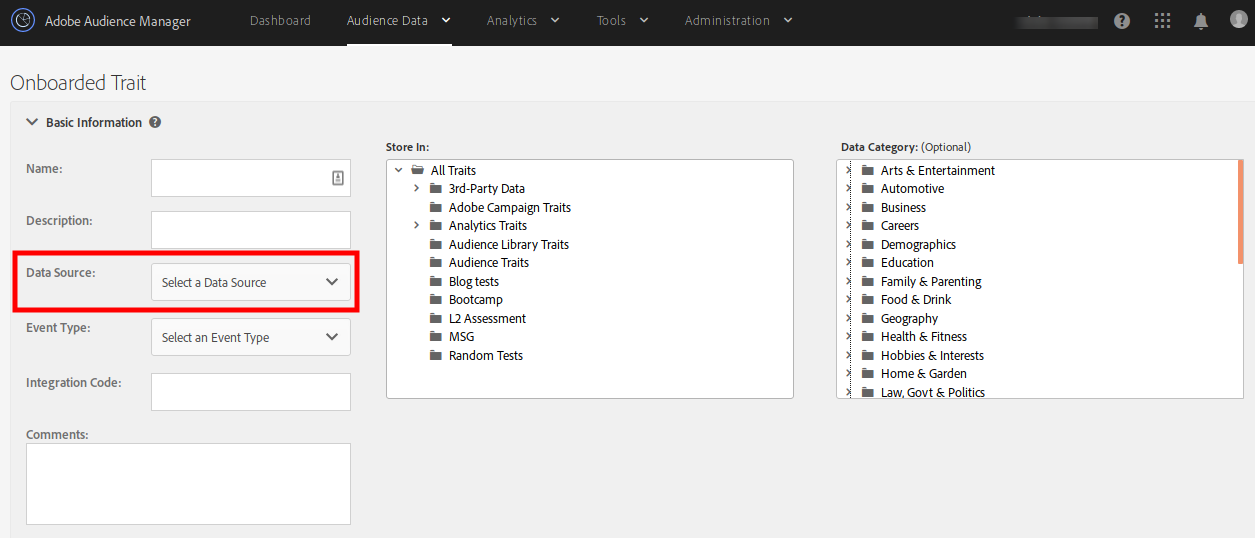
Choosing the wrong data source will mean that AAM will ignore your traits. This is the simplest case.
ID Storage
A less known functionality of the AAM data sources is to store IDs. Just by creating a new data source in AAM, you also get a new ID storage where you can send IDs, either by using a declared ID or an ID sync. The way I see it is like a table, where the rows are the devices and the columns the data sources. This table is stored at AAM level, which means that is shared across all AAM customers. As a consequence, it makes it conceptually huge: billions of rows and hundreds of thousands of columns. Obviously, AAM does not really use a SQL or Excel table, which would be really slow.
| UUID | Data Source 1 | Data Source 2 | Data Source 3 |
|---|---|---|---|
| 12345 | a1b2c3 | d4c5e6 | |
| 67890 | abcde98765 | ||
| 98765 | x9z8y7 | hijklm1357 | t5y6u7 |
| 43210 |
It is worth nothing a couple of things:
- The primary key for AAM is the UUID (demdex cookie).
- There will be gaps, many gaps. Usually, a UUID will only have an ID sync with a handful of data sources.
What is even more surprising is these IDs are used in destinations. I know, this sounds really confusing: data source IDs in destinations? However, if you think a bit more about it, it makes sense. Why create a new ID storage for destinations, when you already have one. As an AAM user, you should not care about this, but if you are implementing AAM and need to get a batch file from it, you will need to think about the data source ID you want the data to be keyed off. This is also used with DSPs.
Core Services
You will have noticed that, after using AAM for some time, you have multiple data sources, some of which you did not create. The Adobe provisioning team will create some of them, whereas others are created automatically. The reason is that AAM delivers some Core Services features and they require a data source. One example is the sharing of Analytics segments with the Experience Cloud.
In reality, the Core Service is using either the data onboarding feature or the ID storage, but hidden behind a different front-end.
Data classification
This is the main reason for writing this post. In a turn that looks even more difficult to follow, when you select a data source for a trait or segment, you are actually classifying it. This causes a lot of confusion in the following 2 cases, as people do not know what to choose in this mandatory field:
- Rule-based traits. These are based on real-time calls to AAM edge servers. No matter which data source you choose, all rule-based traits are evaluated in every AAM call. We usually create a “Analytics” data source, but this is just for convenience; AAM will not restrict the traits in there to those coming from Server-Side Forwarding.
- Segments. Creating a segment from traits from the same data source might not require to think too much, but what happens when you combine traits from multiple data sources? Which data source do you choose?
The truth is that it does not matter, from a processing perspective, what data source you choose in the previous 2 cases. AAM will still behave as you expect. You may wonder, then, “why do I need to choose a data source”? There are, at least, two reasons:
- User permissions. As I will show in a later post, you can create user groups and restrict the access based on data source. This is particularly important when you have multiple tenants or multiple agencies working with your AAM instance.
- Look-alike modelling. When creating a model, you must choose a list of data sources. Only the traits in the selected data sources will be included in the model.
I hope that, after reading this post, you understand a bit better AAM data sources.