
Why a data layer is a good thing
14 Jun 2015 » Data Layer
Back in the old days, when we used the traditional division between an s_code and on-page code, the concept of a data layer made little sense. The developers had to add some code server-side to generate the on-page code. Gathering the information to be captured was a server-side issue: the CMS would have to collect the information from one or various sources (CMS DB, CRM…) and present it on-page, so that, when calling s.t(), the s object would have all needed information.
However, now that tag managers are becoming the norm, the previous approach does not work well. There is no on-page code; all code is generated in the tag manager and injected to the page through it. This means that, in order to track some data, it must already be in the HTML code or in other resources available to JavaScript, like query string parameters or cookies.
One might think that, as long as the required information is visible on the page can be extracted using CSS selectors, we are safe. Consider the requirement to capture the city in the delivery address and this code:
<table id="delivery-address">
<tr>
<td class="city">London</td>
</tr>
</table>
Using the selector #delivery-address .city, we should be able to extract “London”. But, what if the developers decide to change the id or the class? What if there is a new requirement to completely remove this data from the web page? Our tracking will be broken and, if this happens a few months after the release, we will probably not know why.
The most reliable solution is to add a JavaScript object, completely independent of the rest of the HTML code, with all the relevant information of the web page. Then, the tag manager just needs to reference directly the elements in the JavaScript object. The developers can then change anything in the HTML code and, as long as this JavaScript object is kept intact, the tracking will continue working.
There are many ways to create a data layer, but all fall into two categories: create a custom data layer or follow a standard. I will never recommend to create a custom data layer. There are a few standards that are worth mentioning:
- AEM client context. This is the de facto standard that comes with AEM. I have spoken with AEM developers and all say that this can be used in many cases.
- JSON-LD. I have never worked with this one, but one of my clients was already using it. More information here: json-ld.org.
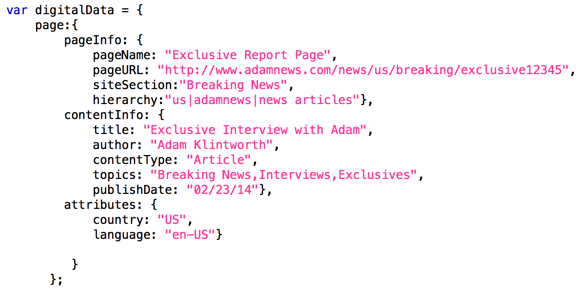
- W3C Customer Experience Digital Data Layer. I always recommend this standard, as it has been produced by the W3C (the same body standardising the Web) and Adobe took a role in this standardisation, together with other companies like Google, IBM, Red Hat… The previous image is an example of how the data layer would look like in this case. The standard itself is freely available: http://www.w3.org/2013/12/ceddl-201312.pdf.
In future posts, I will add some details about the last standard.
[UPDATE 16/08/2022] I do not recommend the W3C Customer Experience Digital Data Layer (CEEDL) any more. See my post on the EDDL