
Understanding AEP Identities
08 May 2022 » Platform
Now that you understand what the Experience Data Model (XDM) is, let’s move to another critical element of the AEP puzzle: identities. In theory, they look simple but, under the hood, they can become complex and difficult to manage.
In one of my first posts on AEP, Introduction to the Adobe Experience Platform - Part 2, I briefly touched on the concept of identities and the identity service. You may remember the following diagram:
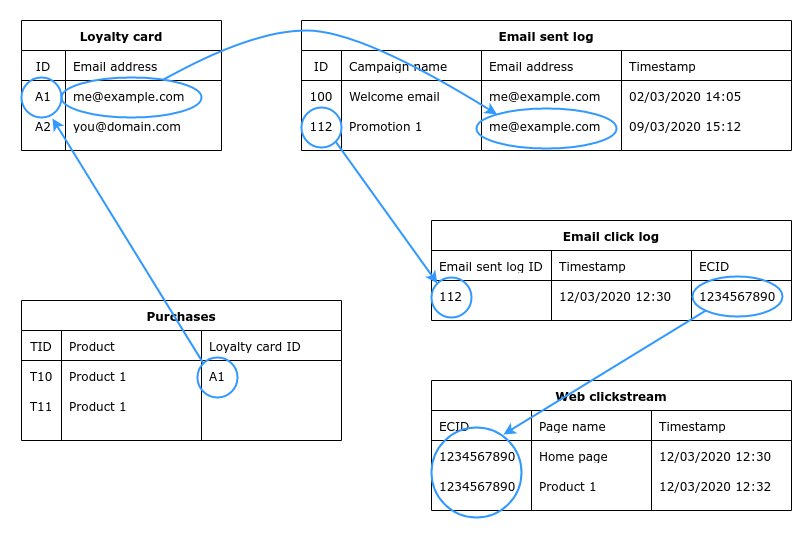
Today I am going to do a deep dive into this concept.
Primary vs additional identifiers
One way of classifying the identifiers in a schema is by the following division:
- Primary. This is a mandatory field in an AEP schema. This means that all entries in a dataset that use this schema must have a value for this field. You can choose (almost) whatever field you want in the schema, as long as it is unique. Think of it as the primary key in an RDBMS. As such, there can only be one primary identity per schema. You configure it by checking the “Identity” and the “Primary identity” checkboxes for the field.
- Additional. Once you have a primary identifier, you can choose as many additional identities as you want. Entries in a dataset may or may not have a value for additional identities. You configure them by only selecting “Identity”.
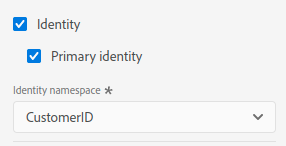
Let’s use an example to make it easier to understand. When ingesting data in AEP from a CRM, we expect all entries from the CRM to have a CRM ID (the primary identifier). We also expect to have an email address, but it may not be present in all cases (additional identity).
Namespaces
In the previous screenshot, you will have noticed that there is an extra mandatory configuration parameter for identity fields: the namespace. The documentation (I suggest you review this page, as it has clear diagrams) defines a namespace as:
[…] namespaces are a component of Identity Service that serve as indicators of the context to which an identity relates.
Another way of understanding it is as a pool of identity values. As we will see a bit below, AEP looks for matches within a namespace to link profile fragments in a single unified profile. Another objective of the namespace is to keep different identity types separated. For example, 12345 may be a CRM ID and an ECID and we want AEP not to merge profiles due to this random coincidence. As we will see a bit below, AEP looks for matches within a namespace to link profile fragments in a single unified profile.
There are many out-of-the-box namespaces and you should use them in the first place. Only if there is nothing that matches your identity type, you should create a new namespace. Typical examples are email, ECID, phone…
Identity graph
Identities are very important for a reason: to build an identity graph. An identity graph is a constellation of IDs that belong to the same customer. This capability is central to any CDP and I would argue that it is the single most important capability. The rest of the capabilities that any CDP offers stem from this one. You could think of AEP as an engine that is fixated on finding matches in identity namespaces.
While this is by no means the algorithm that is used, it will help you understand how the identity graph works:
- AEP ingests data from a data source into a dataset.
- If the fragment does not contain the primary identifier, it is discarded.
- AEP looks for the value of primary identity in its namespace.
- If the value is not found, it is added to the namespace.
- For each additional identity that is present in the entry: a. A link between the primary and the additional identities is stored in the identity graph. b. If the value of the additional identity is not found in its namespace, it is added.
The end result is that, in the identity graph, all identifiers within the various namespaces that correspond to the same customer, are linked. If I query the identity graph with a pair namespace:identity, I will get in return all other identities that are linked to it. This is what the unified profile does:
- For a given identity, it searches for its identity graph
- It looks for all fragments that correspond to all the identities in the graph
- Using the merge policies, it generates the profile
What makes a good identifier?
I have mentioned it above and I will reiterate it here again: identity fields must have a strict 1:1 relationship with the customer. This is what I mean by unique. If there is a possibility that two or more customers share the same value in an identity field, you must look for other identities.
When working with data sources, one of the key tasks during the discovery phase is to find their primary and additional identifiers. Look for the following fields in the data sources, which tend to be good candidates:
- Email address
- CRM ID
- Primary keys generated by a database
- ECID
- Order ID
I would not recommend the telephone number, as the carriers recycle those that are not used anymore.
Although this seems like a straightforward task, my experience shows that it is not that simple. Be prepared to face situations like:
- Due to legacy reasons, different databases may use different IDs, which are not compatible between them.
- Various profiles may be sharing the same email address. For example, parents using their email address also for their children.
- The entities that the data sources send to AEP do not represent individuals. For example, a bank client may have multiple bank accounts.
- Legal reasons prevent sharing the IDs with AEP.
The solution? Well, while I am not an expert in data science, I believe there is no standard approach to come up with a unique ID that will work with AEP. You will need to get creative and evaluate different options. It may help to know that, using data prep, you can combine fields and create hashes of fields.