Hybrid ECID

As I explained in my EMEA Summit lab, you should not use the ECID server-side if you are in a web environment. The solution I proposed was to use a hybrid approach. This means that the ECID must still be generated client-side, and then used server-side.
Summit Lab: Server-Side Digital Marketing

Last Thursday (16/05/2019) I delivered my very first lab at an Adobe Summit. I would like to thank all of you who attended. It went really well and many participants managed to do the full exercise. I have received many requests to publish the content or explain more. There is so much to explain, that I will write multiple posts in the coming weeks, to cover all aspects. Use the comments if you need more clarifications.
Adobe EMEA Summit 2019
I will be conducting a lab at the Adobe EMEA Summit. I will show how to implement Server-side Digital Marketing on Thursday at 14:00. If you want to know more about it, please join me! If you are at Summit, but cannot attend my lab, I will be at the Adobe stand most of the time. See you there!
Server-side PHP Library
When, a few months time ago, I started writing the series of blog posts on Server-side digital marketing, I did not initially know what to expect. If the number of comments per post is a valid survey method, then I can now say that this series has been the most popular in my blog so far. I have even received internal requests from colleagues about this topic after reading one of these posts.
Of Visits and Sessions

As I have said a few times, it is very easy to measure page views. I have also explained how to measure visitors. There is, though, another typical question to answer: how many times has a visitor visited our website? Seems like a simple question, right? Well, it turns out, measuring visits is not that simple.
Visitor Identification

Welcome back to another basic post about the Adobe Experience Cloud. One of the main pillars of any web analytics tool is the visitor identification. It is not only used for the visitors metric, but also as the basis of multiple other features in tools like Target and Audience Manager.
Multi-tenancy in Adobe Target

After a few weeks delay, I am resuming the multi-tenancy in the Adobe Experience Cloud series of posts. I had an issue with my internal sandbox, which prevented me from showing how to set up multi-tenancy in Adobe Target. I got it fixed this week and I am ready to show it to you. Let’s start!
DSP isolation

I once encountered a concerning situation with an agency, which required immediate action. If you are using agencies for your display advertising campaigns and you have recently acquired a license for AAM, then this post is for you.
The User-Agent (Part II)

This is the second part of the User-Agent mini series. I split the topic into 2 posts, as it was getting too long. If you have not read the first part, I recommend you start with it. I will now explain how Adobe uses the User-Agent HTTP parameter in the different tools.
The User-Agent (Part I)

The User-Agent parameter is a piece of information that all browsers attach to all HTTP(S) requests they make. In today’s post, I will demystify this HTTP parameter and explain how it works. There will be a second part, where I will explain how this parameter is used in Adobe products.
Adobe Analytics Data Warehouse

I tend to write about new features of Adobe tools or “cool” ways of using it. That does not mean that I have forgotten about good old features and this is what I am going to do today, explain one of the basic tools of Adobe Analytics: Data Warehouse.
Authentication and authorisation in the AEC

In the last few months, I have been writing about how to manage users in the Adobe Experience Cloud (AEC). However, I have noticed that there are two concepts that people do not understand well: authentication and authorisation. I should have known better, as I did not know the difference well enough until not long ago. My purpose today is to clarify these two concepts in the scope of the AEC.
Adobe Target Segments

Adobe Target segments are probably the richest among the SaaS tools of the Adobe Experience Cloud. Target itself has segmentation capabilities, but it can also use segments coming from multiple other sources. Here you will see how to use all of them.
Multi-tenancy in Audience Manager
Now that I have clarified the data sources in Audience Manager, I can explain how to manage multi-tenancy in Audience Manager. If you have not read that post, please do so before proceeding with this one. But if you have, let’s get started!
Data Sources in AAM

When you are new to AAM and you hear the words “data sources”, you immediately think you understand the concept. However, as you progress in your knowledge of the tool, you start to realise that you actually do not know what data sources are in AAM and need to rethink all you have learned. At least, this is what happened to me. Over time, I have finally understood this concept and today I wanted to share it with you in this post.
Multi-tenancy in Adobe Analytics

A few weeks ago I introduced the concept of multi-tenancy in the Adobe Experience Cloud. Adobe Analytics has had support for multi-tenancy for a very long time. Recently, all user administration for Adobe Analytics has been moved to the Admin Console, where you now configure everything. Read on if you want to know how to configure multi-tenancy in Adobe Analytics with this new setup.
Real-Time Reports

Today I am going to explain one of those features you rarely use, but it can be very useful in certain circumstances: real-time reports in Adobe Analytics. As its name implies, with this feature you can get certain reports in real-time.
Server-side Adobe Target

This is the last post on the server-side everything series, at least for now. While I prepared the material for this post, I realised an interesting fact. Adobe Target does not require a lot of technical knowledge, when used on websites. However, server-side Adobe Target is the most complicated of all server-side implementations. Let’s see why.
Adobe Analytics Attribution IQ
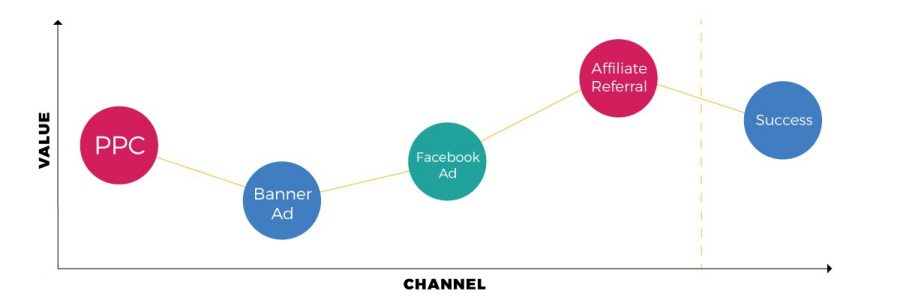
Until last Thursday, I had an idea of what would this week’s post was going to be about. However, on Friday, it all changed. I saw the internal presentation of Attribution IQ and I changed my mind. I know there are a few series I have not finished, but I think this is more important. But do not worry, I will resume my other series soon. Let’s dive into Attribution IQ!
Multi-tenancy in the Adobe Experience Cloud
It is not too uncommon that you need to have multiple tenants in the Adobe Experience Cloud. Although it was not explicitly designed to support this feature, it is possible to achieve it. I must admit it is not straight forward, but not difficult either. I will start with an introduction to multi-tenancy and, in future posts, I will explain the details for each solution.